常见的统一标识符算法(UUID、NUID、Snowflake)
在日常开发过程中,肯定少不了接触“统一标识符”,一般我们都直接使用各个语言标准库中的实现,例如在Java中可以使用java.util.UUID.randomUUID()来获取。使用UUID的场景各不相同,那该怎么选择统一标识符算法呢?
UUID
通用唯一识别码(英语:Universally Unique Identifier,UUID),是用于计算机体系中以识别信息数目的一个128位标识符,还有相关的术语:全局唯一标识符(GUID)。 根据标准方法生成,不依赖中央机构的注册和分配,UUID具有唯一性,这与其他大多数编号方案不同。重复UUID码概率接近零,可以忽略不计。 - 《通用唯一识别码》 - Wikipedia
UUID共36位(32个字符+4个连接符号),格式为: xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx, M表示版本,N表示变体。变体是为了保持向后兼容以及能应对未来的变更,在RFC4122标准中有明确定义了变体的取值和作用:
The following table lists the contents of the variant field, where the letter “x” indicates a “don’t-care” value.
Msb0 Msb1 Msb2 Description 0 x x Reserved, NCS backward compatibility. 1 0 x The variant specified in this document. 1 1 0 Reserved, Microsoft Corporation backward compatibility 1 1 1 Reserved for future definition.
UUID目前一共5个版本,每个版本的实现的方式不同,具体每个版本的定义建议看:《UUID版本》- Wikipedia
使用的最多的应该是版本4,例如在Java中的java.util.UUID.randomUUID()就是一个版本4的实现,在多数情况下我们都直接使用该方法获取UUID。
各版本的特点:
版本1
- 基于时间+MAC地址,实现了全局唯一,很适用于分布式系统,几乎不会生成相同的UUID
- MAC地址直接暴露在UUID中,可被追溯
版本2
- 在RFC4122标准中没有明确的定义,大多UUID库根据DCE 1.1的定义实现的或者直接不实现,例如satori/go.uuid库有基于V1实现了V2,而Java中的
java.util.UUID则没有实现V2
- 在RFC4122标准中没有明确的定义,大多UUID库根据DCE 1.1的定义实现的或者直接不实现,例如satori/go.uuid库有基于V1实现了V2,而Java中的
版本3、版本5
- 版本3和版本5除了使用的算法(版本三使用了MD5,而版本5使用了SHA-1)不同外,其余部分都相同
- 基于命名空间,不同命名空间生成的UUID一定不会相同
- 相同命名空间,不同Name生成的值有机率会出现相同
适用场景
- Version 1/2适合应用于分布式计算环境下,具有高度的唯一性;
- Version 3/5适合于一定范围内名字唯一,且需要或可能会重复生成UUID的环境下;
- 至于Version 4,个人的建议是最好不用(虽然它是最简单最方便的)。
通常我们建议使用UUID来标识对象或持久化数据,但以下情况最好不使用UUID:
- 映射类型的对象。比如只有代码及名称的代码表。
- 人工维护的非系统生成对象。比如系统中的部分基础数据。
- 对于具有名称不可重复的自然特性的对象,最好使用Version 3/5的UUID。比如系统中的用户。如果用户的UUID是Version 1的,如果你不小心删除了再重建用户,你会发现人还是那个人,用户已经不是那个用户了。(虽然标记为删除状态也是一种解决方案,但会带来实现上的复杂性。)
NUID
NUID是CNCF组织下NATS项目的一个UID库(从commit来看,应该是2018-03-17才变更到NATS下面的)。项目主页上介绍很简单“A highly performant unique identifier generator.”,看样子在性能方面是极有信心的。该算法的实现代码极少,包含注释一共才135行。
NUID使用62个字符(0-9a-zA-Z)生成22位的结果,结果分为2部分:
- 前12位为真随机数:crypto/rand包(《GoLang中的随机数》- 根号三)
- 后10是伪随机数
主要逻辑有:
- 使用真随机数或者当前时间的纳秒作为伪随机数的随机种子
- 前12位使用真随机数
- 后10位使用伪随机数(使用对伪随机数 /= base 获取到下一次的伪随机数,然后对数进行取余操作获取具体的字符)
前12位的真随机数:
// Generate a new prefix from crypto/rand.
// This call *can* drain entropy and will be called automatically when we exhaust the sequential range.
// Will panic if it gets an error from rand.Int()
func (n *NUID) RandomizePrefix() {
var cb [preLen]byte
cbs := cb[:]
if nb, err := rand.Read(cbs); nb != preLen || err != nil {
panic(fmt.Sprintf("nuid: failed generating crypto random number: %v\n", err))
}
for i := 0; i < preLen; i++ {
n.pre[i] = digits[int(cbs[i])%base]
}
}
后10位的伪随机数:
// Generate the next NUID string.
func (n *NUID) Next() string {
// Increment and capture.
n.seq += n.inc
if n.seq >= maxSeq {
n.RandomizePrefix()
n.resetSequential()
}
seq := n.seq
// Copy prefix
var b [totalLen]byte
bs := b[:preLen]
copy(bs, n.pre)
// copy in the seq in base36.
for i, l := len(b), seq; i > preLen; l /= base {
i -= 1
b[i] = digits[l%base]
}
return string(b[:])
}
生成的结果示例: M4bZr7xyO3toV6T6iC7lWB
Benchmark结果:
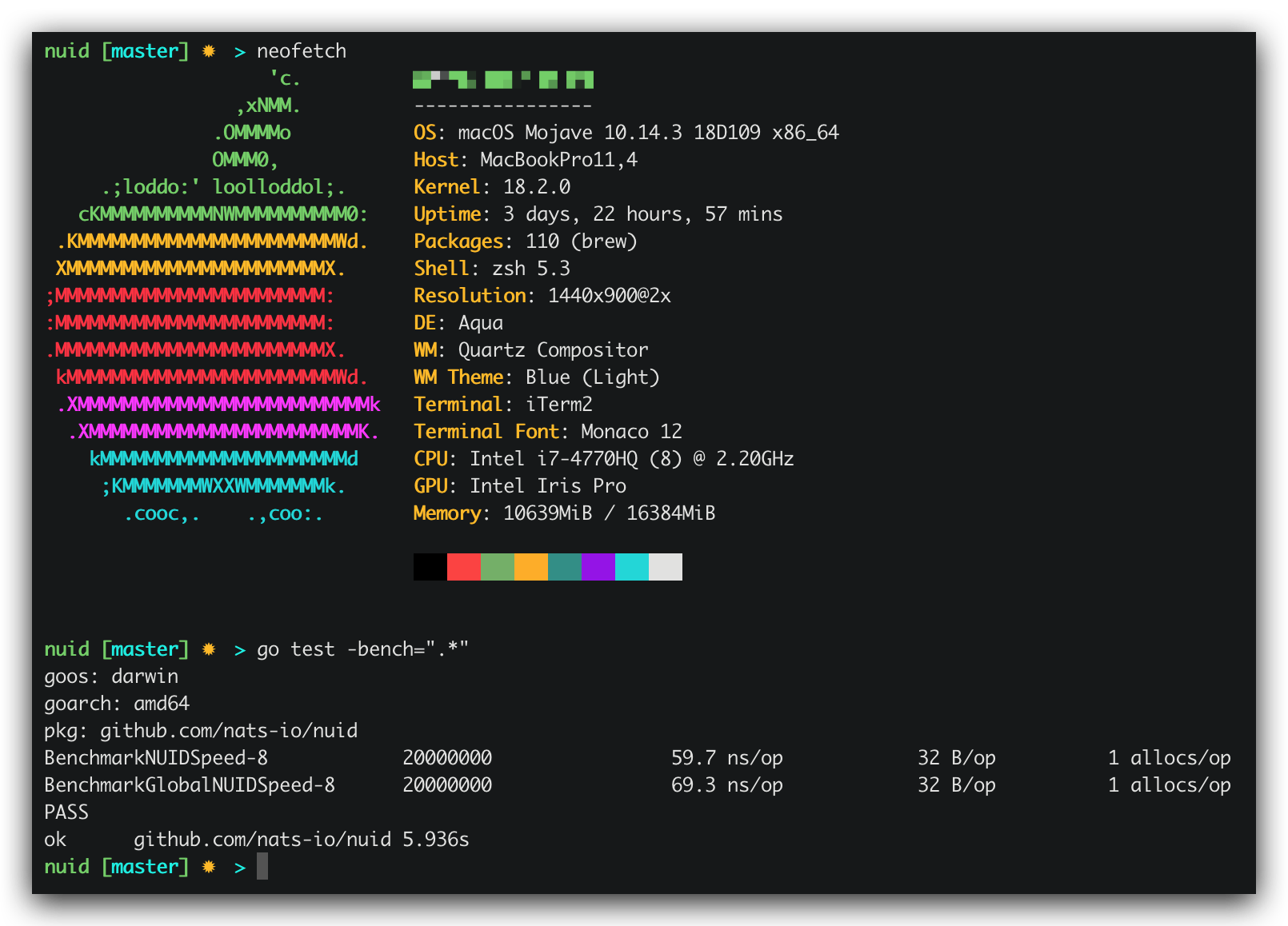
适用场景
- 仅用来做标识符,无其他作用(例如排序)
- 支持高并发
Snowflake
Snowflake(雪花算法)是Twitter推出的在分布式环境生成唯一ID的算法。
雪花算法的组成格式如下(1+41+10+12 = 64):
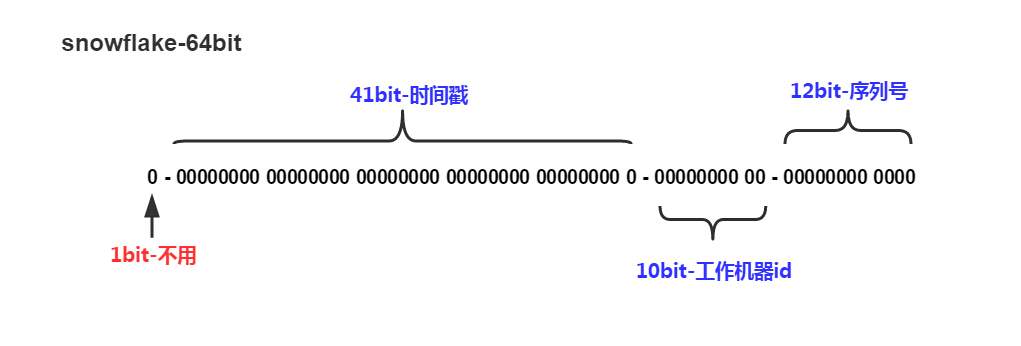
关于雪花算法的文章很多,本文最后贴出了相关文章,我就不再赘述了。以下主要说说雪花算法的特点:
- 有序
- 支持分布式(最大分布式节点为1023台)
- 一毫秒内可以产生4095个ID
- 基于系统时钟
基于以上特点,Snowflake的适用场景很明确:
- 能支持排序
- 大规模的分布式环境
- 能支持高并发
需要注意的是:由于中间主要的41位是根据系统时钟生成的,如果某机器的系统时钟发生了调整(回拨),那么可能导致生成重复的ID。
Leaf
Leaf是美团开源的分布式UID生成服务,支持两种生成ID的模式:
- 号段模式(segment,基于数据库)
- 雪花算法模式(Snowflake)
其中,基于Snowflake的实现使用了Zookeeper来尝试避免因系统时钟回拨导致可能生成重复ID的问题,具体逻辑如下图所示:
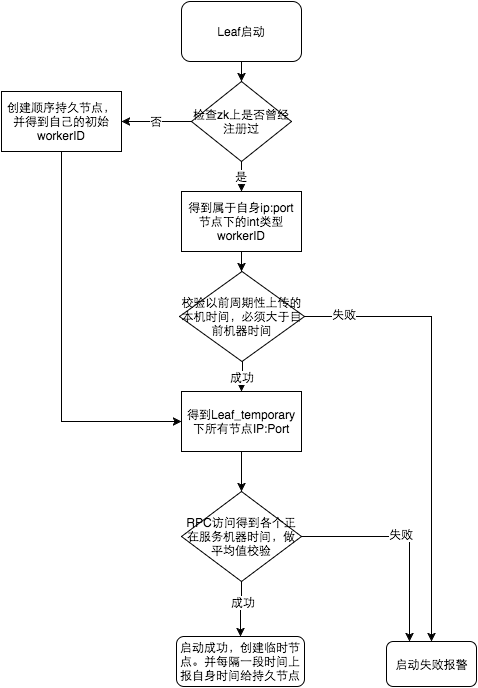
关于美团Leaf以及其他UID方案的优缺点可以看看《Leaf——美团点评分布式ID生成系统》- 美团技术团队
相关引用
UUID
NUID
Snowflake
Leaf
Go